DECLARE @CurrentDate DATETIME
DECLARE @CurrentDateStr VarCHAR(200)
DECLARE @CloseTime int
DECLARE @CTRLTIME Date
DECLARE @DCFLG CHAR(1)
DECLARE @TERMID CHAR(5)
DECLARE @Exist_Cnt int
DECLARE @REC_Cnt int = 0
DECLARE @REC_Cnt_MAX int = 60
DECLARE @Delay_Time int
DECLARE @Delay_Time_MAX int = 60
DECLARE @Temp_ABCD TABLE(
[TERMID] char NOT NULL,
[DCFLG] char NOT NULL,
[AAAA] char NOT NULL,
[BBBB] [int] NOT NULL,
[CCCC] varchar NULL,
[ANS] char NULL,
[ANSCODE]char NULL
);
SET @Delay_Time = 10
SET @Delay_Time_MAX = 60
Declare CUR_ABCD CURSOR FOR
SELECT TERMID
,DCFLG
,BBBB
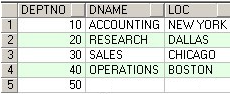
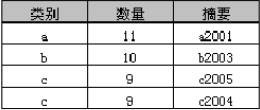
FROM [KKKK_Common_C].[dbo].[ABCD]
SET @CurrentDate = (SELECT GETDATE())
SET @CurrentDateStr = CONVERT(varchar,@CurrentDate,120)
PRINT ‘@CurrentDateStr = ‘ + @CurrentDateStr
SET @CloseTime = CAST(SUBSTRING(@CurrentDateStr,12,2) as int)
PRINT ‘@CloseTime = ‘ + CAST(@CloseTime AS VARCHAR)
WHILE @REC_Cnt < 10
BEGIN
OPEN CUR_ABCD
FETCH NEXT FROM CUR_ABCD
INTO @TERMID, @DCFLG, @CTRLTIME
WHILE @@FETCH_STATUS = 0
BEGIN
IF @DCFLG = '1'
BEGIN
SET @Delay_Time = CAST(datediff(second,@CTRLTIME,getdate()) as int)
IF @Delay_Time > @Delay_Time_MAX
BEGIN
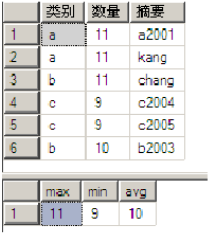
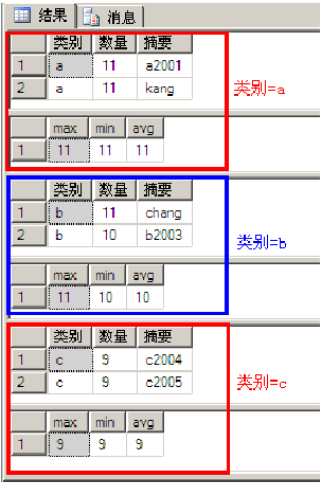
SELECT @Exist_Cnt = COUNT(*) FROM @Temp_ABCD WHERE [TERMID] = @TERMID AND [CTRLTIME] = @CTRLTIME
IF @Exist_Cnt = 0
BEGIN
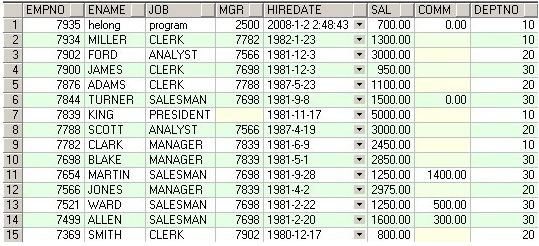
INSERT INTO @Temp_ABCD SELECT* FROM [KKKK_Common_C].[dbo].[ABCD] WHERE [TERMID] = @TERMID
END
END
END
FETCH NEXT FROM CUR_ABCD
INTO @TERMID, @DCFLG, @CTRLTIME
END
CLOSE CUR_ABCD
SELECT @REC_Cnt = COUNT(*) FROM @Temp_ABCD
waitfor delay '00:00:00:10'END
DEALLOCATE CUR_ABCD
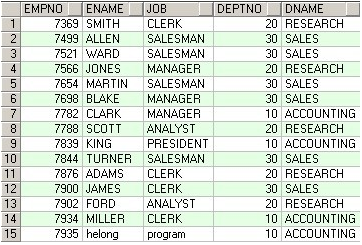
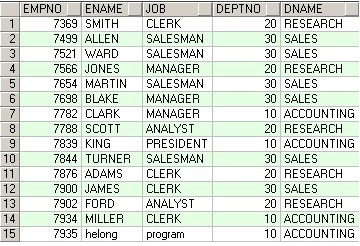
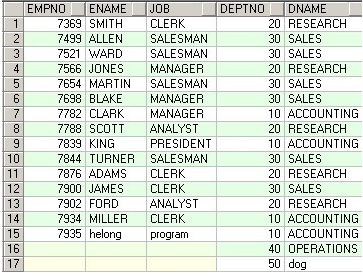
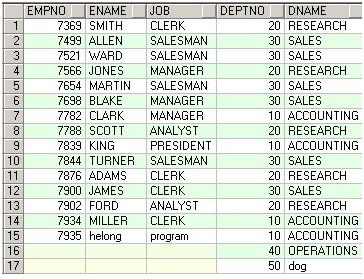
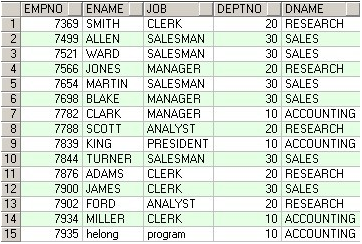
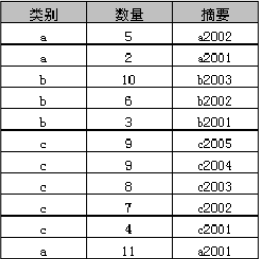
SELECT * FROM @Temp_ABCD